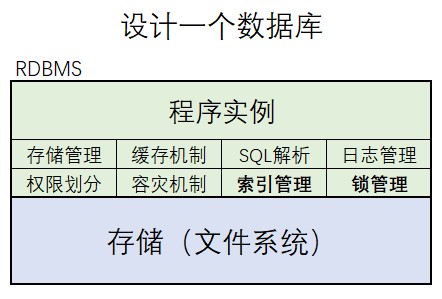
关系型数据库——索引
关系型数据库包括:
- 架构
- 索引
- 锁
- 语法
- 理论范式
B-Tree索引
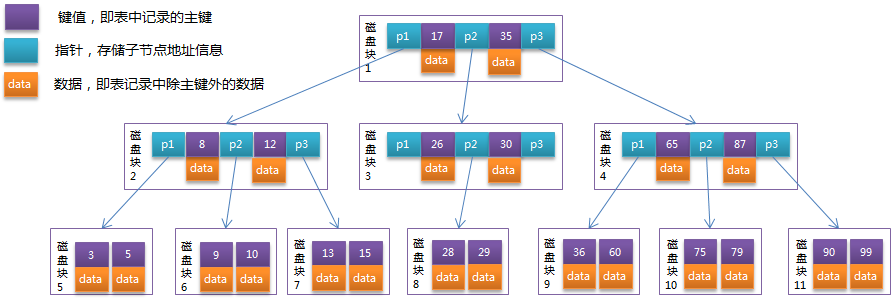
定义
- 根节点至少包括两个孩子
- 树中每个节点最多包含m个孩子(m>=2)(m阶树)
- 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子
- 所有叶子节点都处于同一层
- 假设每个非终端节点中包含有n个关键字信息
- 关键字按照升序排序
- 关键字个数 (ceil(m/2) - 1) <= n <= m - 1 (每个节点关键字个数比指针少一个)
- Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
B+-Tree索引
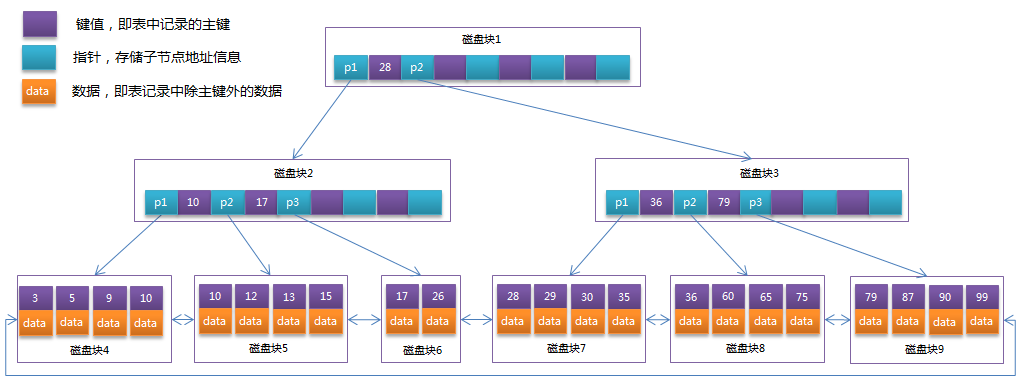
图片来源:BTree和B+Tree详解
B+-Tree与B-Tree的区别
- 非叶子节点的子树指针比关键字个数相同多1(也有相同的版本)
- 非叶子节点仅用来索引,数据都保存在叶子节点中
- 所有叶子节点均有一个链指针指向下一个叶子节点(数据链表)
B+-Tree优势
- 磁盘读写代价更低(内部结构没有数据,内部节点更小,一次性读入内存的节点更多)
- 查询效率更加稳定(所有查询长度相同)
- 有利于数据库扫描(叶子节点有链表,可以进行范围查询)
Hash索引
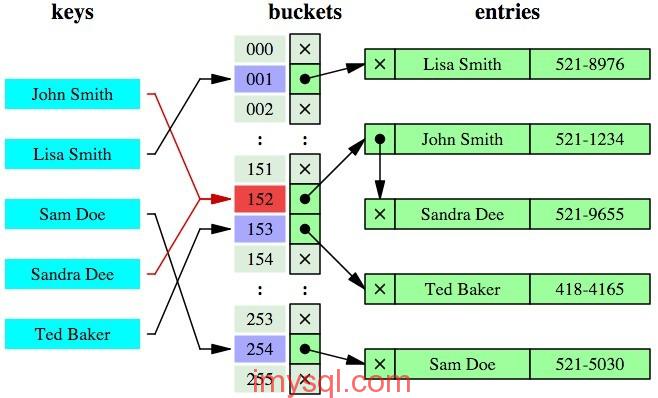
简单地说,哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
B+-Tree和Hash索引区别:
- 等值查询,hash索引有绝对优势,只需要经过一次算法即可找到相应的值;如果键值不是唯一的,需要先找到该键所在的位置,再根据链表往后扫描,知道找到相应数据
- hash索引无法胜任范围查询,经过hash算法后,无法判断数据范围
- hash索引不支持多列联合索引的最左匹配规则
- 有大量重复键值的情况下,hash索引效率比较低(因为hash碰撞)
BitMap索引(不常考)
位图索引主要针对大量相同值的列而创建。拿全国居民登录一第表来说,假设有四个字段:姓名、性别、年龄、和身份证号,年龄和性别两个字段会产生许多相同的值,性别只有男女两种值,年龄,1到120(假设最大年龄120岁)个值。那么不管一张表有几亿条记录,但根据性别字段来区分的话,只有两种取值(男、女)。那么位图索引就是根据字段的这个特性所建立的一种索引。
以及这个文章通俗易懂的介绍了位图索引:位图索引:原理(BitMap index)
聚簇(聚集)索引和非聚簇索引的区别
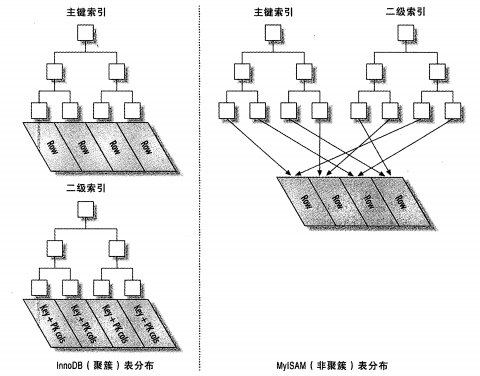
图片来源:详解聚簇索引
聚簇索引:
- 叶子节点存的是整行数据,直接通过聚簇索引的键值找到某行
- 数据的物理存放顺序与索引顺序一致
- 一个表只能有一个聚簇索引
- (这也是MySQL中InnoDB表必须存在主键的原因,因为整张表是聚簇索引,默认通过主键聚集数据,如果没有定义主键,则选择第一个非空的唯一索引,如果没有非空的唯一索引,则利用自增的行号隐式作为聚集索引)
非聚簇索引:
- 叶子节点存放的是字段的值,通过非聚簇索引的键值找到对应的聚集索引字段的值,再通过聚集索引键值找到表的某行(辅助索引的用法)
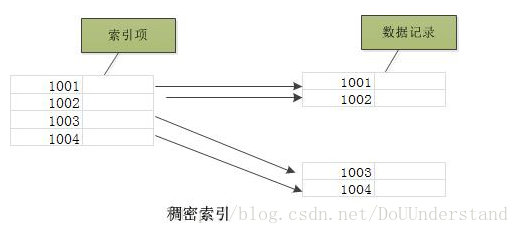
密集索引与稀疏索引
稠密(密集)索引:InnoDB必须有且仅有一个密集索引
稀疏索引:MyISAM主键索引,唯一键索引,普通索引均为稀疏索引
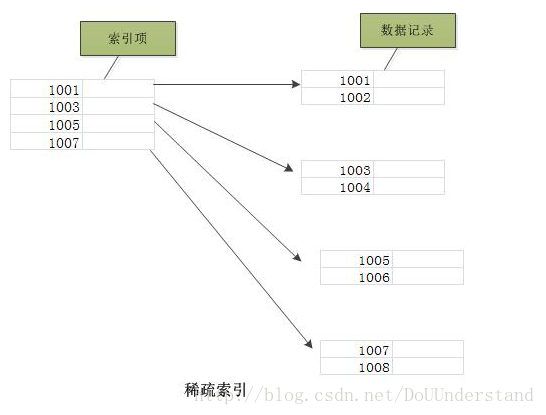
稠密索引能够比稀疏索引更快的定位一条记录。但是,稀疏索引相比于稠密索引的优点是:它所占空间更小,且插入和删除时的维护开销也小。
相对于稠密索引,稀疏索引只为某些搜索码值建立索引记录;在搜索时,找到其最大的搜索码值小于或等于所查找记录的搜索码值的索引项,然后从该记录开始向后顺序查询直到找到为止。
最左匹配原则
- 最左前缀匹配原则,MySQL会一直向右匹配直到遇到范围查询(>,<,between,like)就停止匹配(例如a=3 and b = 4 and c > 5 and d = 6在已建立的(a,b,c,d)顺序的联合索引,d是用不到索引的,但如果索引为(a,b,d,c)则都可以用到,其中a,b,d顺序可以任意调整)。
- =和in可以乱序,比如a=1 and b=2 and c=3建立(a,b,c)索引可以任意顺序,MySQL查询优化器会自动识别成索引可以识别的格式。
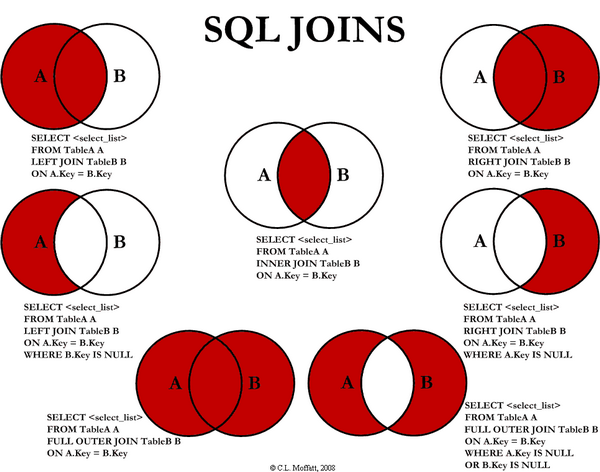
JOIN